传统方法局限

金融界中,投资组合的优化问题始终是关键挑战。以往资产分配的方法有不少缺陷,比如Markowitz的经典模型虽然能估算出投资组合的收益,但在交易频繁的市场环境中,它显得不够有力,这主要是因为它依赖预测收益而非真实收益来计算。传统金融的计量分析方法以及诸如DEA、模拟退火等复杂算法,难以把握投资组合权重的实时变动,导致无法做到资产配置的最优化。这往往使得实际投资中的决策面临难题。
传统方法通常把调整投资组合的比重看作是不变的做法,忽略了时间的流动和资产配置因交易而变化的事实。因此,当面临金融市场复杂多变的情况时,这些方法往往难以灵活应对,常常不能适应市场的变动,结果是投资效果不理想,很多投资者使用这些传统方法投资,都没能获得预期的收益。
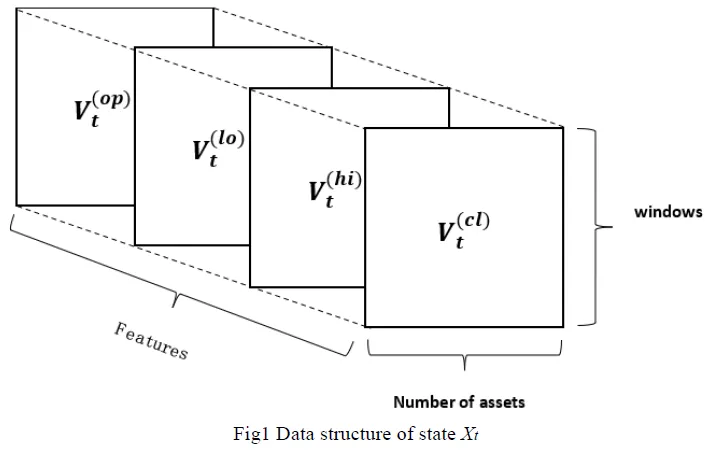
DRL模型优势
深度强化学习模型在投资组合优化方面表现出显著优势。数据显示,该模型年化回报率可达19.56%,夏普比率更是高达1.5550,充分证明了其在风险调整后的收益能力。通过实际数据验证,Trust钱包官网入口这一模型在有效降低风险的前提下, TrustWallet官方网址为投资者实现了可观的收益。
https://www.hsfengji.comDRL是一种基于数据的动态优化模型,有助于降低主观误差。在具体交易中,它能够更公正地根据市场数据来调整资产配置,更贴近市场现状。与传统方法相比,DRL不易受人为干扰,为投资者提供了更为科学的投资策略。
现有DRL问题
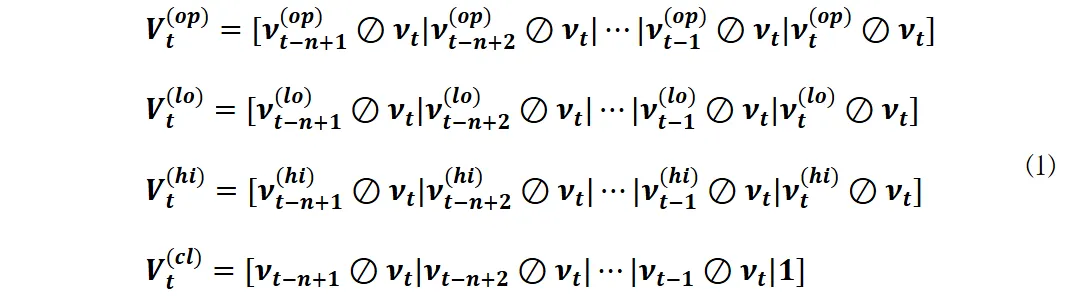
现有的DRL投资组合优化模型存在不足。该模型主要依赖投资组合回报的奖励机制,但在我国股市的表现并不理想。因此,研究者们不得不改用固定的投资权重进行回测,这显然与DRL模型的本意相悖。这种情况限制了该模型在特定市场环境中的实际应用效果。
一些研究者在采用深度强化学习技术调整资产分配时,未充分注意神经网络结构的构建以及资产权重的限制,这可能导致模型在实际操作中表现不稳定,甚至违背投资的基本准则,进而削弱了投资组合的优化成效。

新奖励函数提出
为了提升深度强化学习在资产优化方面的能力,研究人员们已经开发出了若干新颖的奖励机制。比如,Wu团队采用了定制的夏普比率奖励函数,而Almahdi团队则是将Calmar比率与递归强化学习相结合来优化资产。这些创新尝试为DRL模型的发展指明了路径。

本项研究特别为Actor-Critic算法打造了夏普比率奖励机制,这不但提升了模型的稳定性,还进一步优化了动态投资组合的调整流程,从而使模型在应对市场波动时能更精确地调整资产配置。
研究验证应用
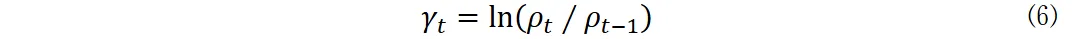
本项研究在长仓限制条件下,运用DRL模型对CSI300的成分股投资组合进行了优化,并且与多种计量经济学优化模型进行了全面对比。实际数据的检验表明,DRL模型在资产配置优化方面展现出显著的效果。
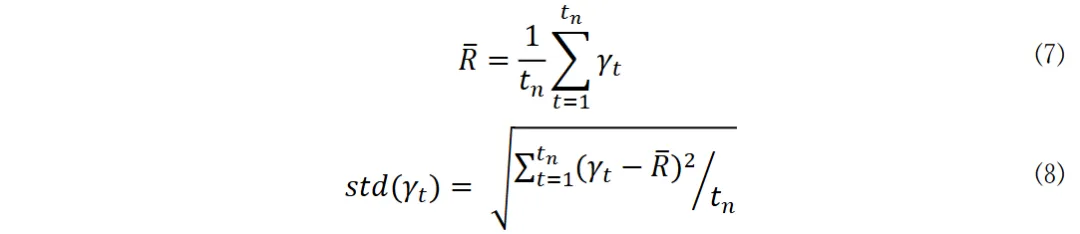
在分析框架里,纳入了诸如均值方差模型、条件风险价值等多样化优化模型。这些模型主要聚焦于降低风险以及提高夏普比率。同时,PPO算法构建的投资组合展现了优异的风险与收益比,这也进一步彰显了深度强化学习在投资组合管理领域的应用前景。
研究成果意义

这项研究为学术界贡献了一种新的投资组合优化策略,同时也为后续学术探索带来了新的思考路径和导向。在未来的学术研究中,学者们可以依托这一成果进行更深入的挖掘和探究。
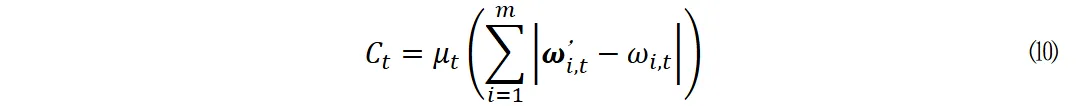
实际投资组合管理中,这一成果带来了实用的方法,揭示了在实战中资产比重灵活调整的巨大可能。投资者利用这些研究,能更优地安排资产,从而提升投资收益。
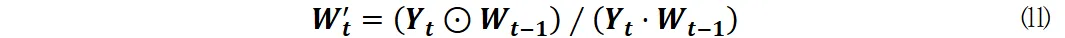
您觉得深度强化学习在投资组合优化领域将占主导地位吗?欢迎留言、评论,并对文章点赞和转发。
